
EU Targets Prediction Markets: Why Retail Investors May Soon Be Blocked
The Rise of Prediction Markets: Why Regulators Are Concerned What was once a niche pursuit for political junkies and data enthusiasts has…


For years, the industry has chased the promise of the “infinite” context window, operating under the assumption that if we simply feed enough raw data into an Large Language Model (LLM), the model will eventually synthesize that information into perfect insights. However, as we move from laboratory experiments to real-world deployment, this strategy has hit a hard wall of diminishing returns. The core issue is that context windows are not merely passive storage; they are computationally intensive environments that demand massive amounts of memory for every single token processed. When we push models to ingest hundreds of thousands of tokens, we are not just increasing costs—we are actively degrading the model’s ability to reason effectively.
One of the most persistent hurdles in this approach is the well-documented “lost-in-the-middle” phenomenon. Research has consistently shown that when information is buried deep within an oversized context block, LLMs tend to prioritize data at the beginning and the end of the prompt while glossing over the middle sections. This architectural fragility means that a larger context window does not automatically translate to better retrieval; instead, it often introduces significant noise that distracts the model from the specific facts it needs to solve a problem. Essentially, the more “context” we provide, the more we dilute the signal, forcing the model to struggle through a haystack of its own making to find a single, relevant needle.
The reliance on massive context windows represents a brute-force approach to a problem that requires a surgical solution. Scaling input size is not a substitute for intelligent information retrieval.
Beyond the cognitive degradation of the models, the economic reality of long-context processing is increasingly unsustainable. Every token included in a request adds to the latency of the system and balloons the compute costs for every API call or inference request. This creates a vicious cycle where developers pay a premium for performance that is statistically less reliable than if the model had been provided with a concise, relevant subset of the data. When the cost-to-performance ratio scales linearly with context length, businesses eventually find that their applications become economically unviable as their data stores grow.

To overcome these limitations, we must shift away from the “stuffing” strategy and toward a more structured, granular approach to data management. Relying on massive context windows assumes that the model can act as its own database, but LLMs are designed for reasoning, not for high-fidelity archival storage. By implementing in-memory mapping, we can decouple the storage of vast knowledge bases from the active reasoning process. This allows us to keep the context window lean and focused on only the most pertinent information, thereby ensuring that the model maintains its peak reasoning quality while keeping computational overhead within reasonable bounds.
At its core, in-memory mapping represents a fundamental shift in how we structure the bridge between raw, chaotic information and the high-level reasoning capabilities of Large Language Models (LLMs). Rather than treating an LLM as a monolithic engine that must ingest, parse, and structure vast quantities of raw data simultaneously, this architectural pattern interposes a high-fidelity, queryable layer directly within the system’s memory. By transforming unstructured inputs into a structured, vectorized, or graph-based representation before the model even begins its inference cycle, we create a cognitive buffer. This ensures that the model is not burdened with the “grunt work” of data cleaning or pattern recognition, allowing it to focus its computational power exclusively on complex decision-making and synthesis.
This approach effectively decouples the heavy lifting of data retrieval from the delicate process of inference. Traditionally, developers have relied on disk-based retrieval systems that introduce significant latency, forcing the LLM to wait for I/O operations or struggle with the noise inherent in raw document dumps. In contrast, an in-memory mapping strategy maintains a “mapped reality”—a curated, indexed version of the data—that resides in active memory. Because this data is pre-processed and optimized for rapid access, the system can feed the LLM highly relevant, refined context instantaneously. This transition from a reactive, pull-based model to a proactive, state-aware architecture significantly diminishes the overhead that often leads to context window congestion and performance degradation.

The reduction in LLM processing overhead achieved through this method cannot be overstated. When a model is forced to parse unstructured data, it spends a vast majority of its tokens—and thus its compute budget—attempting to identify relevance and filter out noise. By offloading these tasks to an in-memory layer, developers can ensure that only the most dense, semantically meaningful information reaches the model’s input layer. This not only improves the overall speed of the system but also enhances the precision of the output. When the LLM interacts with a pre-indexed, “mapped” version of the world, it encounters fewer hallucinations and experiences a marked improvement in logical consistency, as the foundational data is already structured for clarity.
In-memory mapping acts as a sophisticated cognitive buffer, transforming disparate streams of raw information into a coherent, queryable knowledge graph that the LLM can reference with surgical precision.
Ultimately, this architectural shift allows for a more scalable approach to AI application development. By managing the data lifecycle in a dedicated, high-speed memory layer, organizations can process orders of magnitude more information without exhausting the context window of their primary model. This strategy transforms the LLM from a disorganized data processor into a refined analytical engine, capable of maintaining focus on high-value tasks while the in-memory layer handles the heavy, repetitive work of data organization and retrieval. As we move toward more complex agentic workflows, the ability to maintain this clean, mapped context will become the standard for building efficient, reliable, and high-performing AI systems.

Traditional Retrieval-Augmented Generation (RAG) often relies on broad semantic searches that dump entire document chunks into an LLM’s context window. While this method provides the model with relevant materials, it frequently introduces “context noise,” where extraneous information competes with the core query. By transitioning to in-memory mapping—using high-performance structures like spatial indexes, hash maps, or optimized key-value stores—we can shift from a “bulk delivery” model to a “surgical extraction” model. This approach ensures that the LLM receives only the most precise, verified data points necessary to answer a specific question, effectively narrowing the scope of the model’s output to verifiable facts rather than probabilistic associations.

The primary advantage of in-memory mapping lies in its ability to bypass the latency and inaccuracies inherent in searching through massive vector databases in real-time. By pre-processing data into highly structured, memory-resident indexes, the system can perform localized lookups with near-instantaneous speed. Instead of asking a model to “find” information within a large text block, the application layer acts as a gatekeeper, pinpointing the exact coordinates or keys associated with the user’s intent. Because the model is no longer required to sift through irrelevant noise, the “attention” mechanism within the LLM is focused exclusively on the relevant facts, which drastically diminishes the likelihood of the model hallucinating details to fill in cognitive gaps.
By grounding an LLM in high-fidelity, in-memory data, we transform the model from a creative writer into a precise analytical engine that operates within the boundaries of known, verifiable truth.
When an LLM is provided with a massive, unstructured context, its reasoning capabilities are often diluted by the burden of parsing the data itself. Conversely, structured data extraction through in-memory layers forces a logical discipline upon the model. Because the data is delivered in a clean, consistent format—often stripped of redundant conversational filler—the model can dedicate its internal processing power to logical inference and synthesis rather than filtering. This grounding technique creates a “truth-bound” environment where the model is explicitly constrained by the retrieved data. As a result, users benefit from higher accuracy, faster response times, and a significant reduction in the confidently stated errors that typically plague large-scale generative systems. By treating memory as a high-performance index rather than a bottomless bucket, we effectively enable LLMs to perform as high-precision instruments for enterprise-grade decision making.

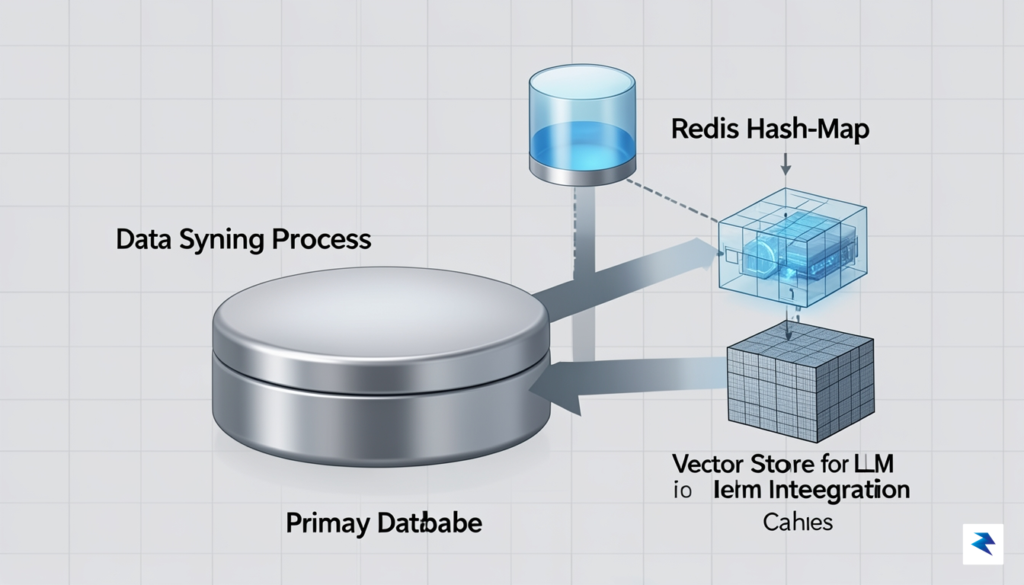
Building a robust in-memory layer requires a multi-tiered technical architecture that moves beyond simple key-value caching. At the foundation of this stack, developers frequently leverage high-performance data structures like Redis or DragonflyDB to handle rapid, transient access to structured metadata. However, when dealing with the high-dimensional data typical of LLM workflows, these standard caches must be augmented with specialized vector stores such as Milvus or Pinecone. By deploying a hybrid approach—where exact matches are retrieved via hash-mapping and semantic intent is resolved through vector similarity search—systems can achieve sub-millisecond latency while maintaining the nuanced understanding required for complex prompt engineering.
To optimize for memory footprint, developers often implement custom memory buffers using systems-level languages like Rust or C++. These buffers serve as a high-speed intermediary layer that minimizes serialization overhead by using flat memory formats like Apache Arrow. By avoiding the common pitfalls of JSON serialization—which can introduce significant parsing delays—these buffers allow the system to stream context directly into the LLM’s input window. This is particularly critical in high-concurrency environments where the overhead of converting data formats can quickly become a bottleneck, leading to increased token costs and latency spikes that degrade user experience.
The core of a high-performance retrieval system lies in the synchronization logic; the memory layer must act as a near-real-time mirror of the primary database without introducing consistency lag that could confuse the model.
Synchronization between the primary database and the memory layer is arguably the most difficult aspect to scale effectively. Implementing a change-data-capture (CDC) mechanism is essential here, as it ensures that updates in the source of truth propagate immediately to the memory buffers. Rather than relying on periodic polling, which wastes compute cycles and risks serving stale data, developers should utilize event-driven architectures where database write-ahead logs (WAL) trigger near-instantaneous invalidation or updates in the cache. This ensures that the LLM is always operating on the most current information, even as the underlying data evolves at high velocity.
For high-concurrency environments, optimization techniques such as request coalescing and intelligent eviction policies are paramount. Request coalescing groups similar retrieval queries into a single batch operation, significantly reducing the pressure on the underlying vector indices during peak traffic. Furthermore, employing LRU (Least Recently Used) or LFU (Least Frequently Used) eviction strategies tailored specifically to the semantic relevance of the data prevents the cache from becoming bloated with low-utility tokens. By carefully balancing these strategies, engineering teams can create a resilient system that scales linearly with user demand while shielding the LLM from unnecessary context-window overload.

While in-memory solutions offer unparalleled speed for enriching LLM interactions, providing instant access to vast amounts of contextual data, their inherent resource intensiveness poses significant challenges in a production environment. The allure of near-instant data retrieval must be balanced against the practicalities of managing substantial memory footprints, which, if left unchecked, can lead to instability, performance degradation, and exorbitant operational costs. Effectively navigating these trade-offs requires a strategic approach that encompasses careful memory management, robust scaling architectures, and vigilant monitoring to ensure both performance and cost efficiency.
One fundamental aspect of managing in-memory layers is understanding and optimizing garbage collection (GC) processes. While automated GC is a convenience in many modern programming languages, aggressive memory allocation and deallocation within high-throughput LLM applications can trigger frequent GC cycles, potentially introducing “stop-the-world” pauses that degrade real-time performance. Developers must therefore delve into language-specific GC tuning parameters, such as heap sizes and collection thresholds, to minimize these disruptions. For highly sensitive, low-latency applications, exploring languages with more explicit memory management or leveraging memory pools can provide finer-grained control, ensuring that memory reclamation is predictable and non-disruptive.
Beyond optimizing garbage collection, the effective management of in-memory data hinges critically on intelligent cache eviction policies. As memory resources are finite, a robust strategy is essential to decide which data to retain and which to discard when new information needs to be stored. Two common policies are Least Recently Used (LRU) and Least Frequently Used (LFU). LRU is effective for data exhibiting strong temporal locality, prioritizing the removal of items that haven’t been accessed for the longest duration. Conversely, LFU excels when certain data points are consistently popular over time, even if not accessed *just* recently, by evicting items with the lowest access count. More advanced, adaptive policies, or hybrids like LRU-K (which considers K-th access), can combine the strengths of these approaches, dynamically adjusting to the specific access patterns of the LLM application’s contextual data to maximize cache hit rates and minimize expensive data reloads.
Relying on a single node for a massive in-memory data layer creates an obvious single point of failure and severely limits scalability. Horizontal scaling, therefore, becomes imperative for production-grade LLM applications. This involves distributing the in-memory layer across multiple nodes, effectively sharding the data. Partitioning strategies, such as consistent hashing on specific keys (e.g., embedding IDs or user session tokens) or range-based partitioning, ensure that data is evenly spread and can be retrieved efficiently from the correct node. However, this introduces complexity, as requests might need to consult multiple nodes if the LLM prompt requires information from different partitions. Careful design of the data schema and query patterns is essential to minimize cross-node communication, maintaining the low-latency benefits of in-memory access while providing robust fault tolerance and virtually limitless scalability.
In Kubernetes-centric deployments, robust monitoring is non-negotiable for managing memory-intensive LLM applications. Tools like Prometheus and Grafana provide invaluable insights into crucial metrics such as `container_memory_usage_bytes`, cache hit ratios, and eviction rates. Setting appropriate resource `requests` and `limits` for in-memory layer pods ensures that they receive adequate resources without monopolizing cluster capacity, while also preventing disruptive Out-Of-Memory (OOM) kills. For high-traffic LLM applications, cost optimization is equally critical. Implementing intelligent auto-scaling mechanisms, such as Horizontal Pod Autoscalers (HPA) reacting to memory pressure or custom metrics, allows the infrastructure to dynamically adjust to demand. Furthermore, leveraging cloud provider features like memory-optimized instance types and exploring the use of spot instances for less critical, fault-tolerant components can significantly reduce operational expenditure without compromising overall system performance or reliability.

We are currently witnessing a fundamental transition in how we build artificial intelligence, moving away from the era of monolithic, “all-knowing” models toward a landscape dominated by orchestrating architectures. Previously, the industry focus was placed almost exclusively on training larger models to internalize vast amounts of static information. However, this approach has hit a wall of diminishing returns, characterized by prohibitive latency and the constant struggle against finite context windows. By shifting toward in-memory mapping, developers are effectively decoupling the reasoning engine from the data storage, allowing the LLM to act as a high-speed navigator rather than a bloated, all-purpose repository.
This architectural shift is not merely a technical optimization; it represents the maturation of AI into a modular, reliable utility. When an LLM can offload complex spatial or temporal queries to an in-memory layer, it frees up its internal parameters to perform what they do best: sophisticated logic and nuanced decision-making. This separation of concerns ensures that the system remains responsive even under heavy real-time loads. As these memory-efficient patterns become standard, we can expect a new generation of applications that function with sub-millisecond precision, effectively bridging the gap between raw machine intelligence and the dynamic, real-world data environments that define our daily lives.
The future of AI is not found in building a bigger brain, but in building a better nervous system—one where memory and reasoning are perfectly synchronized for real-time performance.
Looking ahead, the long-term potential for this architecture lies in the development of truly spatial-aware intelligent agents. Imagine autonomous systems that do not just “understand” text but maintain a constant, real-time internal map of their surroundings, allowing for fluid navigation and contextual awareness that current models simply cannot achieve. These agents will operate with a level of reliability that makes them suitable for critical infrastructure, robotics, and complex logistics, where hallucination is not an option and speed is a requirement. By mastering in-memory mapping today, developers are essentially laying the foundation for an ecosystem where AI acts as a seamless extension of our operational capabilities rather than a disconnected tool.
Ultimately, the developer workflow of tomorrow will prioritize composition over training. The most successful AI engineers will be those who treat memory as an active participant in the reasoning loop, meticulously mapping data to be accessible, immediate, and high-fidelity. As we move toward this future, the goal remains clear: to create systems that are not only smarter in their conceptual understanding but significantly faster and more stable in their application. By embracing these architectural paradigms, we are not just solving a temporary bottleneck; we are defining the trajectory of intelligent systems for the next decade.
You must be logged in to post a comment.

