
The Evolution of HTTP Methods: Beyond GET and POST

For over three decades, the architecture of the web has been governed by a relatively small set of verbs defined in the original HTTP specifications. At the heart of this system, GET was designed to be a “safe” and idempotent operation, intended strictly for the retrieval of resources. It assumes that the request does not change the state of the server, allowing browsers and proxies to cache results aggressively. Conversely, POST was established as the workhorse for everything else; it is a non-idempotent method used to submit data, trigger side effects, or handle complex instructions that do not fit the narrow definition of a simple fetch.
This binary reliance on GET and POST worked exceptionally well when the web was primarily a collection of static documents. However, as modern applications transitioned into sophisticated, data-driven platforms, this rigid paradigm began to show its seams. Developers frequently encounter a persistent “semantic gap” when building APIs that require complex filtering, multi-faceted search criteria, or large request bodies for read-only operations. Because GET requests are restricted by URL length limitations and are discouraged from carrying a request body, developers are often forced to shoehorn complex query parameters into long, unmanageable URL strings, or worse, misuse POST for operations that are fundamentally intended to be read-only retrieval tasks.

Misusing POST for data retrieval creates significant architectural headaches, particularly regarding caching and security. Since POST is defined as state-changing, intermediate proxies and caches are often configured to ignore or bypass it entirely to ensure safety, stripping away the performance benefits that GET provides. This leaves developers in an impossible position: either they sacrifice the performance of caching by using POST, or they compromise the integrity of their API design by attempting to fit intricate query logic into a URI that was never designed to hold it.
The introduction of the
QUERYmethod acts as the missing piece in the HTTP puzzle, offering a standard way to perform safe, cacheable, and body-based data retrieval without the semantic baggage ofPOST.
To bridge this divide, the industry has formally adopted RFC 9265, which introduces the QUERY method. This new standard is designed specifically for scenarios where the client needs to submit a complex payload to retrieve data, but does not want to trigger a state change on the server. By providing a dedicated method for these operations, QUERY clarifies the intent of the communication, allowing web infrastructure to handle these requests with the appropriate level of optimization. This evolution marks a necessary shift toward a more expressive HTTP protocol, ensuring that modern APIs can be both performant and semantically sound.
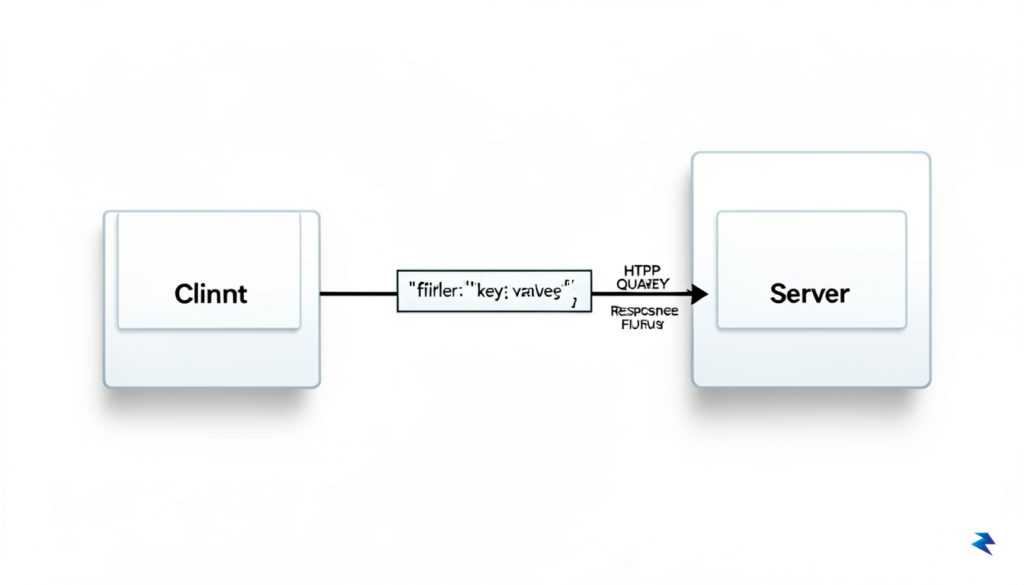
Decoding the HTTP QUERY Method
The introduction of the QUERY method, formally standardized under RFC 9265, represents a significant evolution in how client-server architectures handle data retrieval. For years, developers have struggled with the limitations of the GET method, which restricts query parameters to the URL string—a constraint that becomes problematic when dealing with complex filters, massive payloads, or sensitive search criteria that could inadvertently leak into server logs. Simultaneously, the industry has long relied on the POST method as a “catch-all” for search operations. While functional, using POST is semantically inaccurate because it implies a state-changing action, potentially confusing caching mechanisms and security proxies that expect POST requests to modify the underlying data.
By providing a dedicated method for read-only requests that require a body, the QUERY method bridges this semantic gap. It is explicitly defined as a safe and idempotent operation, meaning that executing the request multiple times will not change the state of the server. This distinction is vital for developers who prioritize building robust, predictable APIs. Because it is recognized as a safe operation, infrastructure components like intermediate caches and load balancers can handle QUERY requests with the same level of optimization as GET requests, ensuring that performance remains high without compromising the cleanliness of the API design.
The technical advantages of adopting this standard are manifold. First, it eliminates the “URL length” barrier; complex operations, such as nested filtering with JSON objects or intricate graph-based queries, can now be passed in the request body rather than being crudely serialized into a URL. This significantly improves the readability of request logs and debugging processes. Furthermore, using QUERY prevents the unintended side effects associated with POST, such as triggering unnecessary cache invalidations or failing to leverage read-optimized pathways in the server architecture. By standardizing this approach, RFC 9265 ensures that modern APIs can support sophisticated search capabilities while maintaining full compliance with the core principles of RESTful design.
The
QUERYmethod effectively solves the long-standing dilemma of how to perform complex data lookups without sacrificing the safety, cacheability, or semantic purity of the HTTP protocol.
Ultimately, transitioning to QUERY is a move toward more professional, future-proof API infrastructure. As developers continue to build increasingly data-heavy applications, the need for a protocol-level solution that supports large, complex, and read-only inputs will only grow. Adopting this standard now allows teams to move away from “hacky” workarounds and toward a cleaner, more intuitive architecture that aligns perfectly with the intended behavior of the web’s foundational request-response model.
Why GET and POST Fall Short in Modern APIs
For years, developers have been forced to navigate a “pick your poison” dilemma when designing complex search interfaces. Traditionally, the GET method has been the go-to choice for retrieving data, relying on query parameters embedded directly within the URL. However, this approach hits a hard technical wall when dealing with sophisticated, multi-faceted filtering. Most browsers and web servers impose strict limits on URL length—often capped at 2,048 characters—which renders GET useless for intricate queries involving nested logic, complex JSON objects, or lengthy search criteria. When a request exceeds these limits, it is unceremoniously truncated or rejected by the infrastructure, leading to fragile applications that fail the moment a user adds one too many filters.
Faced with these constraints, many developers have resorted to “tunneling” read-only operations through the POST method. While this allows for an infinitely larger payload in the request body, it fundamentally violates the semantic integrity of a RESTful architecture. In the standard HTTP specification, POST is intended for state-changing operations, such as creating a new resource or triggering a process. By misusing it for data retrieval, developers effectively blind the network infrastructure. Intermediate caching proxies, which are designed to optimize traffic by storing responses for GET requests, will almost never cache a POST request because it is assumed to be non-idempotent and potentially destructive. This forces every single search request back to the origin server, unnecessarily inflating latency and wasting computational resources.

The fundamental issue is that
POSTmasks the intent of the request, preventing the broader web ecosystem from treating data retrieval as the cacheable, safe operation it actually is.
Beyond the technical hurdles of caching and size limits, there is a significant security and observability trade-off inherent in the legacy approach. When sensitive or verbose search parameters are crammed into a GET request, they frequently appear in plain text within server logs, browser history, and proxy headers. This leaks metadata that should ideally remain private between the client and the server. Conversely, by forcing these queries into a POST body, developers lose the ability to easily bookmark or share specific search states, as the request body is not part of a standard URL link. The QUERY method emerges as the long-awaited middle ground: it provides the semantic “read-only” safety of GET, while offering the expansive, structured request body capabilities previously trapped within the POST method.
By adopting this new standard, the industry finally moves away from these architectural workarounds. It allows for a clean separation of concerns, where the method itself clearly signals that the server is performing a read-only operation. This clarity empowers proxies and CDNs to safely cache complex search results, drastically improving performance for end-users while ensuring that server logs and URLs remain clean, secure, and manageable. Moving forward, the transition to QUERY is not just a syntax change; it is an essential evolution in how we handle the increasing complexity of modern, data-driven applications.
Security and Caching: The Real-World Benefits

For years, developers have been trapped in a precarious trade-off between the semantic limitations of GET and the operational risks of POST. When a query becomes too complex for a standard URL—exceeding length constraints or requiring sensitive parameters—the industry default has been to tunnel these requests through POST. However, this practice effectively breaks the contract of HTTP caching. Because POST is defined as a non-idempotent operation that may change the server state, intermediate proxies and Content Delivery Networks (CDNs) are strictly forbidden from caching the resulting responses. The QUERY method solves this by explicitly signaling that the request is read-only and idempotent, enabling infrastructure to cache the results just as effectively as a GET request, even when the payload is too large or structured for a query string.
Beyond the performance gains associated with caching, the QUERY method offers significant security improvements regarding data exposure. When developers use GET for complex searches, sensitive data often ends up embedded directly in the URL query string. This is a notorious security anti-pattern because URLs are frequently logged in plain text by browser histories, server access logs, and proxy servers. Furthermore, if a user clicks an external link from the search results page, the sensitive query parameters are often leaked to third-party sites via the Referer header. By moving these parameters into the request body, QUERY ensures that sensitive search criteria remain within the encrypted boundaries of the transport layer, shielded from the common leakage vectors that plague URL-based requests.
The shift toward
QUERYrepresents a maturation of RESTful design, where the protocol finally aligns with the reality of complex, data-intensive web applications without sacrificing security or cacheability.
The architectural handling of request headers also becomes more predictable with this new standard. In standard proxy environments, POST requests often trigger aggressive scrubbing or re-authentication checks because the infrastructure assumes the request might modify the server state. Conversely, QUERY allows proxies to treat the request with the same “read-only” profile as GET, while simultaneously respecting the larger payload size allowed by the body. This creates a streamlined pipeline where security headers—such as Authorization or Content-Type—can be processed without the overhead of the defensive posturing typically reserved for state-changing operations. By adopting this method, organizations can build more robust, performant APIs that are inherently safer by design rather than relying on workarounds that compromise the integrity of the HTTP protocol.
Implementation and Future-Proofing Your API

Integrating the QUERY method into your existing infrastructure requires a strategic approach to both server-side routing and client-side compatibility. Because the method is designed to handle complex search parameters that exceed the length limitations of standard URIs, you must first ensure that your underlying web framework can parse a request body attached to a method that is conceptually similar to GET. Many modern frameworks are already beginning to include middleware support for QUERY, but for legacy systems, you may need to implement custom route handlers that treat the request body as a search filter rather than a resource creation payload. By configuring your routers to distinguish between a standard POST (which alters state) and a QUERY (which is strictly side-effect-free), you maintain the architectural integrity of your API while enabling more sophisticated data retrieval capabilities.
Client-side library support is another critical component of a successful transition. While popular HTTP clients like Axios or the native fetch API can technically be configured to send a QUERY request by manually setting the method and body, full-scale adoption is easier when your SDKs and client wrappers provide first-class support for the method. If you are managing an API ecosystem with a wide range of consumers, consider updating your documentation to provide code snippets that demonstrate how to construct QUERY requests in various programming languages. This proactive documentation helps developers avoid the common pitfall of reverting to POST for read-only operations, which can often lead to confusion regarding caching behavior and proxy handling.
Adopting the
QUERYmethod is not just about changing a verb; it is about embracing a cleaner, more predictable way to handle high-complexity search queries without polluting your URL bar.
For teams managing legacy systems, a gradual roadmap is the most sustainable path forward. You do not need to rewrite your entire data access layer overnight; instead, start by implementing QUERY support for your most complex search endpoints that currently suffer from overly long, messy query strings. Once you have validated the performance and caching benefits in these specific areas, you can systematically expand the support to other parts of your API. Furthermore, staying informed about the ongoing evolution of the RFC standards is vital, as the ecosystem surrounding HTTP methods is constantly maturing. By keeping your implementation modular and aligned with emerging best practices, you ensure that your API remains robust, discoverable, and prepared for the next generation of web standards.


