
The Challenge of Agentic AI Reliability

The transition from traditional chatbot interactions to autonomous agentic workflows represents a fundamental shift in how we conceive of human-computer collaboration. In the chatbot era, the success of an interaction was largely dependent on the quality of a single prompt; if the output was lackluster, the user simply refined their query. However, agentic AI moves beyond this conversational paradigm, tasking systems with executing multi-step goals, interacting with external tools, and making autonomous decisions without constant human intervention. This move toward agency transforms the LLM from a passive text-generator into a proactive worker, which fundamentally changes the requirements for system architecture and oversight.

The core difficulty in this evolution lies in the inherent non-determinism of Large Language Models. Unlike traditional software, where a specific set of inputs reliably produces a predictable output based on hard-coded logic, LLM-based agents function within a probabilistic framework. Because these models generate responses based on statistical likelihoods rather than rigid conditional branches, they can produce slightly different results even when presented with identical scenarios. This variability is a feature when you want creativity, but it becomes a massive liability when you require the precision necessary for enterprise-grade automation. Reliability engineering, therefore, must move away from the expectation of perfect reproducibility and instead embrace the management of confidence intervals and error-correction loops.
Standard software testing methodologies—such as unit testing and integration testing—are notoriously insufficient for these probabilistic environments. In a conventional application, you can map every possible input to a known correct output, but an agentic system operates in a state-space so vast that exhaustive testing is mathematically impossible. You cannot simply “fix” a bug by modifying a line of code when the behavior emerges from the latent weights of a neural network. Consequently, developers must pivot toward robust evaluation frameworks that measure systemic performance through continuous monitoring, semantic validation, and automated “guardrails” that detect when an agent is veering off course.
Reliability in the age of agents is not defined by the elimination of error, but by the implementation of self-correcting mechanisms that can recognize, contain, and recover from non-deterministic failures.
Ultimately, moving from a prompt-engineering mindset to a systems-engineering mindset is the only path toward building truly resilient agents. This requires architects to view the LLM not as a source of truth, but as one component within a larger, verifiable pipeline. By building in layers of deterministic logic around the probabilistic core, engineers can constrain the agent’s behavior, ensuring that even if the underlying model makes a non-deterministic leap, the overall system remains anchored in safe, repeatable, and goal-oriented execution.
Defining the Architecture of Reliable Agents
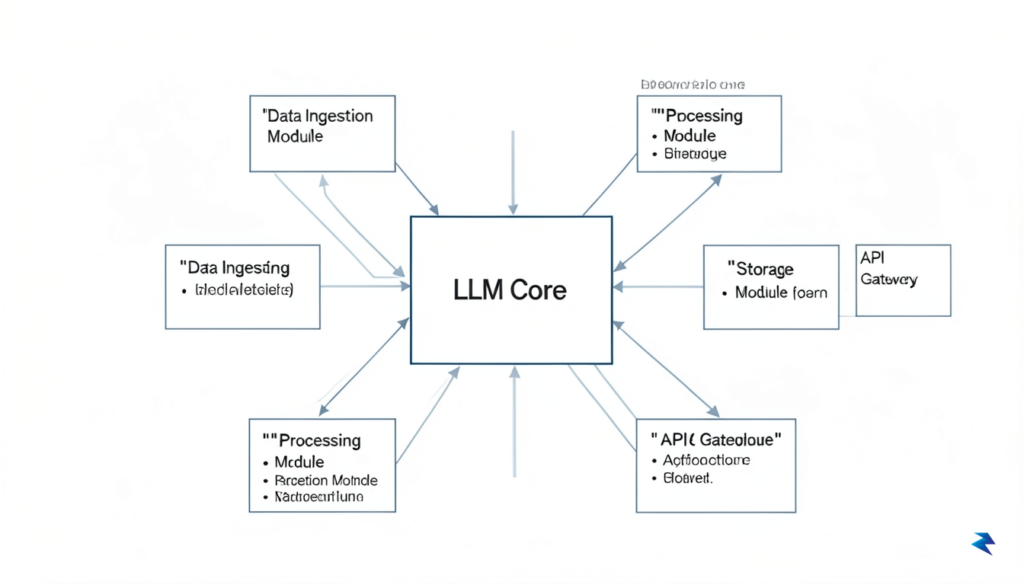
Building a truly reliable agentic system requires moving beyond the “chatty” paradigm of simple prompt engineering and toward a rigid, software-defined architecture. At the core of this transition is the move toward structured outputs, where the agent’s response is constrained by strict JSON schemas or formal grammars. By treating the LLM as a component that must communicate through a predefined interface rather than free-form natural language, we eliminate the ambiguity that often leads to “hallucinations” or unexpected behavior. This interface layer acts as a contract between the reasoning engine and the execution layer, ensuring that whatever the agent produces can be reliably parsed, validated, and processed by downstream code without the risk of silent failures.
Modularity is the secondary pillar of this architectural scaffold, specifically designed to prevent the dreaded phenomenon of “chain-of-thought drift.” In monolithic agent designs, the reasoning process can easily become convoluted as the agent attempts to hold too many variables in its active attention span. Instead, we must decompose agent workflows into granular, specialized modules—each responsible for a single, well-defined task. By decoupling the reasoning engine from the execution layer, we create a system where each sub-agent or tool-use module operates within a sandboxed context. This isolation ensures that if a specific reasoning path begins to degrade or wander off-track, the error is contained within that specific module, allowing the system to backtrack or initiate a recovery protocol without compromising the entire state of the operation.

A reliable system is not merely a collection of prompts, but a scaffold of constraints where every interaction is validated against a strict schema.
State management serves as the final, critical component in maintaining long-term agent stability. As agents perform multi-step tasks, they risk overwhelming the context window with irrelevant or redundant information, which inevitably leads to a decline in reasoning quality. To combat this, developers must implement a persistent state layer that tracks progress, tool history, and environmental variables outside of the immediate prompt context. By utilizing external databases or graph-based memory structures, we can provide the agent with a “summarized state” rather than a raw dump of every interaction. This allows the system to maintain its trajectory over long, complex objectives while keeping the reasoning engine focused only on the most pertinent data, ultimately resulting in a more predictable and robust agentic workflow.
Strategic Error Handling and Feedback Loops
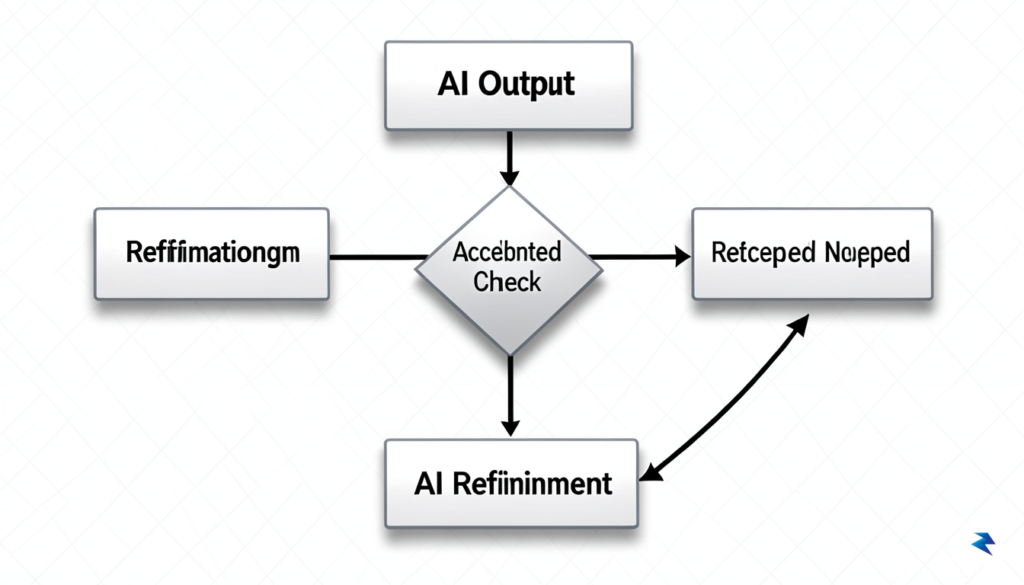
In the landscape of agentic AI, the assumption that a model will execute a perfect chain of reasoning from start to finish is a recipe for system collapse. Instead, professional-grade implementations must treat failure as an expected state. By adopting a “Retry/Refine” pattern, engineers can create a structured environment where an agent is permitted to stumble, provided it possesses the mechanisms to recognize that stumble and correct its course. This often involves wrapping task execution in a loop that checks the validity of the generated output against a set of predefined constraints or logical requirements before the process is allowed to proceed to the next stage.
Implementing the Critic Pattern
One of the most effective ways to mitigate hallucinations or logic gaps is the deployment of a secondary “Critic” agent. Rather than asking a single LLM to perform a task and blindly trusting the result, the system architecture should pass that output to a separate, specialized agent designed exclusively for verification. This Critic agent acts as a gatekeeper, evaluating the primary output against objective criteria, such as factual consistency, adherence to instructions, or the logical soundness of an argument. If the Critic detects a failure, it provides specific, structured feedback to the primary agent, which is then prompted to regenerate its response based on these corrections. This iterative refinement loop significantly narrows the surface area for errors and ensures that the final output has been scrutinized from multiple perspectives.

Beyond logical validation, handling technical failures—particularly those involving external API calls—requires robust exception management. When an agent attempts to utilize a tool and encounters an error, such as a timeout or a malformed JSON response, the system must not simply terminate. Instead, it should employ a “graceful recovery” protocol that captures the error, analyzes the cause, and attempts a self-correction. This might involve re-formatting the query, adjusting the parameters of the tool call, or, if the failure persists, escalating the issue to a fallback process or a human supervisor. By treating these technical hiccups as solvable data points rather than terminal events, you build a system that is resilient enough to function in the messy, unpredictable reality of real-world environments.
Success in agentic systems is defined not by the absence of error, but by the sophistication of the recovery infrastructure surrounding every action.
Ultimately, the goal is to shift from a linear execution model to a recursive, self-correcting one. By combining these feedback loops with clear exception-handling logic, you transform your AI from a fragile script into a robust system capable of handling ambiguity. Whether it is through the deployment of dedicated Critic agents or the implementation of smart retry logic, the ability to catch, diagnose, and remediate errors in real-time is the defining characteristic of a production-ready agentic system.
Testing and Verification Strategies for LLMs
Transitioning from traditional software engineering to building agentic AI requires a fundamental shift in how we approach quality assurance. Unlike deterministic code where a specific input always yields an identical output, LLMs are probabilistic by nature, making standard unit tests insufficient for capturing the nuance of complex reasoning chains. To build truly reliable systems, engineers must move toward evaluation frameworks that treat the agent’s output as a dynamic artifact rather than a static string. This evolution necessitates the implementation of LLM-as-a-judge methodologies, where a stronger or more specialized model acts as an automated evaluator to score the agent’s reasoning steps, factual accuracy, and adherence to system instructions.
The foundation of this validation process is the creation of a “golden dataset”—a curated library of representative prompts paired with verified, high-quality responses. By establishing this ground truth, you create a benchmark that acts as a regression suite for your agent. Every time you update the underlying model, adjust the system prompt, or refine the tool-calling logic, you run your agent against this library to ensure that new optimizations haven’t introduced regressions. This process is essential for identifying “drift,” where seemingly minor changes to a prompt might inadvertently degrade the agent’s ability to handle edge cases that it previously navigated with ease.
Reliability in agentic systems is not a destination but a continuous measurement loop. If you cannot objectively measure the quality of an agent’s reasoning, you cannot improve it.
Beyond content verification, a robust test harness must also track the operational health of the agent. While accuracy is paramount, it is often undermined by excessive latency or prohibitive cost-per-task. A comprehensive evaluation framework should systematically log these metrics alongside the output quality, allowing engineers to visualize trade-offs in real-time. For instance, an agent might achieve higher accuracy through multiple chain-of-thought iterations, but if the total latency exceeds user expectations, the system fails in practice. By integrating these quantitative metrics into your CI/CD pipeline, you ensure that performance remains within acceptable bounds as the system scales in complexity.
Ultimately, the goal is to build a closed-loop feedback system where testing informs refinement. When the “LLM-as-a-judge” identifies a failure, those specific prompts should be added to your golden dataset to prevent future regressions. This iterative cycle transforms testing from a passive gatekeeping activity into an active mechanism for architectural improvement. By treating your evaluation suite as a living document of your agent’s capabilities, you create a safety net that allows for bold experimentation without compromising the integrity of the user experience.
Human-in-the-Loop: Balancing Autonomy and Oversight

The pursuit of full autonomy in agentic systems often seduces engineers with the promise of frictionless efficiency, yet total automation is frequently a dangerous objective in mission-critical domains. In high-stakes environments—such as medical diagnostics, financial auditing, or infrastructure management—the goal should not be to remove the human from the loop, but rather to integrate them as a core component of the system’s architecture. By designing for “meaningful human control,” engineers can build systems that leverage the raw processing power of artificial intelligence while maintaining the nuanced judgment and ethical accountability that only a person can provide. This partnership ensures that agents operate within safe guardrails, transforming the AI from an autonomous black box into a highly capable, supervised collaborator.
To implement this effectively, developers must adopt the “breakpoint” pattern, which strategically pauses agent execution at critical junctures. Rather than allowing an agent to run to completion unchecked, these breakpoints force the system to present its current state, proposed actions, and supporting rationale to a human expert. These interruptions should not be arbitrary; they must be triggered by specific conditions, such as high-uncertainty scenarios, actions that result in irreversible state changes, or decisions that fall outside of pre-defined policy bounds. By embedding these checkpoints into the agent’s workflow, you create an opportunity for a human to intervene, refine, or approve the agent’s trajectory before it commits to an outcome that could have cascading consequences.
Designing for Auditability and Expert Review
The efficacy of a human-in-the-loop system relies heavily on the quality of the information presented during these checkpoints. If a domain expert is tasked with reviewing an agent’s work, they must be able to parse the AI’s reasoning as easily as they would a peer’s report. This requires a UI/UX design that prioritizes transparency over brevity. Instead of just displaying the final output, the system should surface the internal chain-of-thought, citing the specific data points or documents the agent referenced to reach its conclusion. When an expert can quickly verify the logic path, they are significantly more likely to trust the system and catch errors before they propagate into the real world.
Meaningful human control is not just about the ability to hit a ‘stop’ button; it is about providing the human operator with the contextual intelligence required to make an informed decision about whether to proceed, modify, or override the agent’s proposed path.
Ultimately, the most reliable systems are those that facilitate a graceful handoff between machine and human. This involves designing interfaces where the AI acts as a “co-pilot” that suggests solutions, while the human acts as the final arbiter of truth. By investing in clear audit logs, intuitive control interfaces, and well-timed breakpoints, engineers can bridge the gap between autonomous machine capabilities and the requirements of human oversight. This symbiotic approach mitigates the risks associated with AI hallucinations or logic drifts, ensuring that the agent remains a reliable, controllable, and deeply valuable asset in any mission-critical operation.


