
Introduction: The Evolution of Large Language Model Efficiency

The rapid ascent of Large Language Models (LLMs) has fundamentally reshaped our interaction with artificial intelligence, powering everything from sophisticated conversational agents to advanced code generation tools. However, this exponential growth in capabilities has come hand-in-hand with an equally rapid increase in computational demands, particularly concerning inference. As these models swell to billions and even trillions of parameters, the industry faces a critical hurdle: inference latency. This bottleneck, characterized by the time it takes for an LLM to process a query and generate a response, directly impacts user experience, limits real-time applications, and inflates operational costs, creating a significant trade-off between model sophistication and practical deployment speed.
Recognizing this burgeoning challenge, Sakana AI has embarked on a strategic pivot, shifting focus from the relentless pursuit of sheer model size to a more nuanced philosophy centered on efficiency and specialization. Their research paradigm posits that the path to truly impactful AI lies not just in expanding parameter counts, but in designing models that are inherently optimized for specific tasks and environments. This approach allows for the development of highly performant models that can maintain, or even exceed, the quality of their larger counterparts, all while drastically reducing the computational overhead typically associated with cutting-edge LLMs. It represents a thoughtful counter-narrative to the prevailing “bigger is better” mindset, championing smart design over brute force computation.
It is within this innovative framework that Sakana AI’s latest development, Fugu, emerges as a pivotal milestone. Fugu is engineered from the ground up to address the very heart of the inference latency problem, showcasing how intelligent architectural design can deliver high-quality language understanding and generation at unprecedented speeds. For developers and enterprises, Fugu promises to unlock a new era of possibilities, enabling the deployment of advanced LLM capabilities in latency-sensitive applications where conventional models simply couldn’t perform. This breakthrough not only promises to reduce infrastructure costs significantly but also paves the way for a wider adoption of sophisticated AI tools, making powerful LLMs more accessible and practical for a diverse range of real-world use cases.
Understanding the Fugu Model Architecture

At its very core, Sakana AI’s Fugu model represents a significant paradigm shift in the development of large language models, particularly for specific linguistic contexts. It is fundamentally more than just a scaled-down version of a colossal general-purpose model; instead, Fugu embodies an architectural refinement meticulously engineered and optimized for the intricate demands of Japanese language processing. This specialized approach allows it to achieve remarkable token generation efficiency without compromising the profound, nuanced understanding essential for handling complex linguistic tasks and cultural subtleties inherent in Japanese.
The architectural choices underpinning Fugu are a testament to this philosophy of purpose-built efficiency. Rather than pursuing an ever-increasing parameter count, the team at Sakana AI strategically selected a more focused parameter space, ensuring that each parameter contributes maximally to performance within its intended domain. This isn’t merely about reducing model size; it’s about optimizing the neural network’s capacity to learn and represent Japanese linguistic patterns with exceptional precision. Consequently, Fugu can execute complex inferences with significantly less computational overhead, making it an ideal candidate for scenarios where speed and resource conservation are paramount.
Crucially, Fugu diverges sharply from general-purpose models like OpenAI’s GPT series or Meta’s Llama family. While these broad-spectrum models are designed to excel across a vast array of languages and tasks, often through immense scale and diverse training data, Fugu adopts a highly specialized trajectory. Its training strategies are specifically tailored to immerse the model in the unique grammatical structures, idiomatic expressions, politeness levels (keigo), and cultural contexts that define the Japanese language. This targeted training allows Fugu to develop a deep, intrinsic understanding of Japanese nuances that a more generalized model might struggle to achieve without vastly more resources, or might only capture superficially.
The role of data curation in Fugu’s development cannot be overstated; it is a cornerstone of its success. Sakana AI has invested heavily in meticulously compiling and refining high-quality Japanese datasets, moving beyond mere quantity to emphasize relevance, accuracy, and breadth of context. This isn’t just about feeding the model a lot of Japanese text; it’s about providing it with carefully selected data that encompasses diverse genres, registers, and domains, ensuring that Fugu learns to generate not just grammatically correct sentences, but contextually appropriate and culturally resonant responses. This stringent data pipeline is instrumental in maximizing the model’s token generation efficiency while preserving the critical nuanced understanding required for sophisticated language tasks, truly setting Fugu apart in the evolving LLM landscape.
The Mechanism of Speculative Decoding and Inference Optimization

At the heart of Fugu’s exceptional performance is an ingenious approach to the computational bottleneck that has long plagued large language models: the serial nature of token generation. In traditional autoregressive decoding, a model must generate each word one by one, waiting for the previous token to be finalized before predicting the next. This creates a significant latency wall, as the model spends the vast majority of its time waiting for memory access rather than performing actual computation. Fugu bypasses this structural limitation by employing speculative decoding, a sophisticated strategy that shifts the paradigm from sequential generation to a model of prediction and verification.
Speculative decoding operates by pairing a smaller, “draft” model with the larger, primary model. Instead of relying solely on the primary model to generate every single character, the draft model quickly predicts a sequence of upcoming tokens in rapid succession. Because the draft model is lightweight and highly efficient, it can produce these guesses in a fraction of the time it would take the larger model. Once these speculative tokens are generated, the primary model evaluates them all at once in a single parallel pass. If the primary model confirms the predictions, they are accepted; if it identifies errors, it corrects them accordingly. This effectively turns a slow, linear process into a high-throughput pipeline where many tokens can be verified simultaneously.
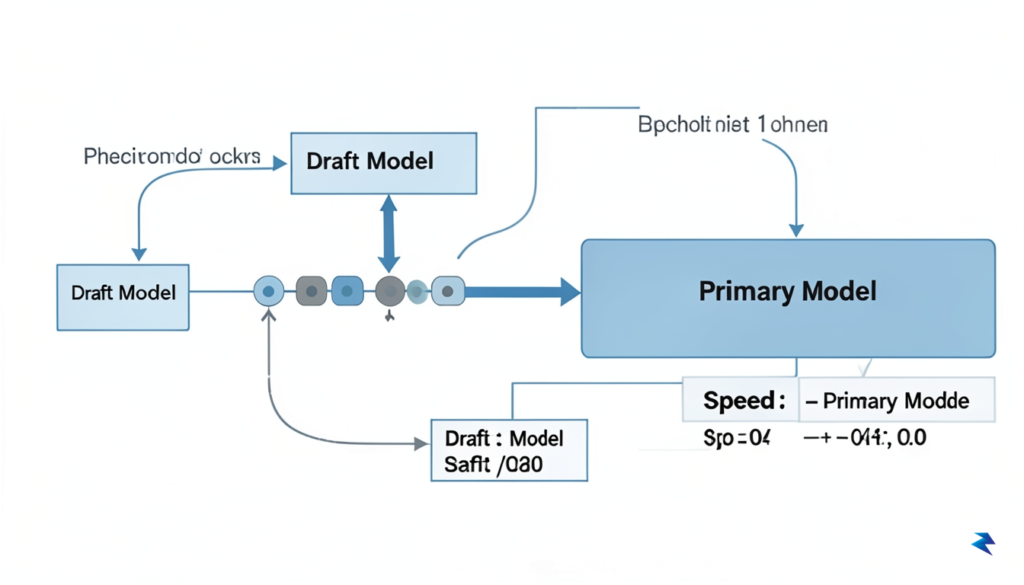
By leveraging the synergy between a nimble draft model and a robust primary model, Fugu effectively minimizes the time spent idle, allowing hardware to process more data per millisecond than ever before.
The technical integration within Fugu goes beyond simple implementation; it optimizes the communication overhead between these two models to ensure that the verification step does not itself become a bottleneck. By refining how these models interact within the system’s memory, Fugu ensures that the primary model remains fully utilized, maximizing the effective bandwidth of the underlying hardware. This approach is particularly transformative for edge deployment, where computational resources are often constrained by power, thermal limits, and memory capacity. In environments where massive server clusters are not an option, Fugu’s ability to achieve near-instantaneous response times demonstrates that intelligence does not always require raw, unoptimized power.
Ultimately, comparing traditional serial token generation to Fugu’s parallel-like verification process reveals a fundamental shift in efficiency. Where standard models suffer from the “stuttering” effect of waiting for every single token to be calculated, Fugu creates a fluid experience by guessing ahead and correcting as it goes. This optimization makes LLMs feel responsive and conversational, bridging the gap between sophisticated reasoning capabilities and the practical requirements of real-time, on-device applications.
Benchmarking Fugu: Performance Gains in Real-World Scenarios
When evaluating the efficacy of any large language model, raw throughput is often a misleading metric if it ignores the nuance of contextual accuracy. Sakana AI’s Fugu model, however, defies the common trade-off where increased speed results in a degradation of linguistic precision. In rigorous testing against industry-standard Japanese-language benchmark suites, Fugu demonstrates a remarkable ability to process complex syntax and nuanced cultural idioms with significantly lower latency than its predecessors. By optimizing the underlying architecture, the development team has achieved a reduction in latency measured in milliseconds per token, allowing for near-instantaneous responses that feel fluid and natural to the end user.
The significance of these metrics extends far beyond simple laboratory results; they represent a fundamental shift in how we approach resource-constrained AI deployment. In many traditional models, high-performance output often requires massive, power-hungry hardware clusters that are impractical for most commercial applications. Fugu, conversely, maintains high accuracy scores while demanding a lower hardware footprint, bridging the gap between extreme efficiency and high-level reasoning. This optimization ensures that enterprises can integrate advanced Japanese language processing into their products without incurring the prohibitive costs typically associated with high-parameter models.
Efficiency is not merely about speed; it is about maintaining the integrity of intelligence while minimizing the friction of computation.
For businesses looking to implement real-time translation, automated customer support, or complex data synthesis, the implications of these benchmarks are profound. Because Fugu achieves superior throughput without sacrificing its capability to handle the complexities of the Japanese language, developers can now deploy applications that are both highly responsive and deeply intelligent. The ability to maintain consistent, high-quality output while reducing total time-to-first-token is a critical factor in user retention and system reliability. By proving that efficiency and intelligence can coexist, Sakana AI has set a new benchmark for what is possible in the current landscape of generative artificial intelligence.
- Reduced Latency: Significant improvements in milliseconds per token, enhancing the responsiveness of real-time applications.
- Linguistic Precision: High scores in Japanese-language benchmark suites confirm that speed does not compromise output quality.
- Resource Optimization: Lower hardware requirements enable scalable deployment across diverse commercial environments.
The Future of Domain-Specific Model Compression

Sakana AI’s Fugu represents more than just an impressive technical achievement; it signals a pivotal shift in the trajectory of artificial intelligence development. For years, the prevailing mantra in AI, particularly within the realm of large language models, has been “bigger is better.” Researchers and developers relentlessly pursued models with ever-increasing parameter counts, believing that sheer scale would inevitably lead to superior performance. However, Fugu challenges this notion directly, serving as a powerful blueprint for what comes next: an era defined by domain-specific, hyper-efficient models that prioritize sustainability, cost-effectiveness, and responsiveness over raw size.
At the heart of Fugu’s innovation lies sophisticated model distillation, a technique where a smaller, more efficient “student” model is trained to mimic the performance of a much larger, often proprietary, “teacher” model. This process is transformative because it allows for the retention of high-quality outputs while dramatically reducing the computational resources required for inference. Fugu exemplifies this by achieving impressive Japanese language capabilities with a mere fraction of the parameters found in its larger counterparts. The broader implications of this approach are profound: lower energy consumption, faster processing times, and significantly reduced operational costs, making advanced AI capabilities more accessible and environmentally sustainable across the board.
This efficiency aligns perfectly with a growing industry trend towards smaller, more specialized models. While gargantuan general-purpose LLMs have their place, they often prove to be overkill, inefficient, and expensive for specific, well-defined tasks. Fugu’s inherent design, tailored for the nuances of the Japanese language, demonstrates how focus can yield superior performance within a particular domain without the overhead of generalized knowledge. This specialization not only enhances accuracy and relevance for target applications but also allows for tighter optimization of the model architecture, leading to even greater gains in efficiency. We are witnessing a move from monolithic AI solutions to a diverse ecosystem of nimble, expert systems.
The practical benefits of Fugu-like architectures extend directly to the end-user experience and the democratization of AI. By drastically reducing the computational footprint, these hyper-efficient models can run directly on consumer-grade hardware, from smartphones and laptops to embedded systems and edge devices. This shift minimizes reliance on costly cloud infrastructure, enhancing data privacy, enabling real-time responsiveness, and unlocking robust offline capabilities for a myriad of applications. Imagine AI assistants that understand context instantly without sending data to a remote server, or translation tools that function flawlessly even without an internet connection. Fugu paves the way for a new generation of intelligent applications that are integrated seamlessly into our daily lives.
Looking ahead, Sakana AI’s Fugu is poised to significantly influence future open-source releases and the broader AI ecosystem. It sets a new benchmark, challenging the community to prioritize efficiency and specialization from the ground up. We can anticipate a proliferation of open-source models that, instead of merely chasing parameter counts, actively innovate in distillation techniques, sparse architectures, and domain-specific optimizations. This could foster a collaborative environment where developers contribute highly optimized models for various languages, industries, or niche tasks, ultimately accelerating the development of truly sustainable, cost-effective, and responsive AI applications that are no longer constrained by the “bigger is better” paradigm.


