The Best MagSafe and Qi2 Chargers for Every Setup (2026)
Understanding the Evolution of MagSafe and Qi2 Charging Wireless charging has long promised a future free from tangled cables, offering…

We are currently witnessing an unprecedented explosion in the demand for large language models, yet this rapid expansion has ushered the industry toward a precarious ceiling. For years, the prevailing philosophy in AI development was that bigger is inherently better, leading to a race for parameter counts that push hardware infrastructures to their absolute limits. As models grow to gargantuan scales, the computational costs and energy consumption required to train and run these systems have become increasingly unsustainable. Organizations are finding that the sheer financial and environmental burden of deploying state-of-the-art AI often outweighs the practical benefits, creating a clear, urgent need for a paradigm shift that prioritizes optimization over simple bulk.
This transition toward parameter efficiency represents the next great frontier in machine learning. Rather than endlessly inflating model architectures, researchers and engineers are now focusing on how to extract maximum reasoning capability from smaller, more agile footprints. The goal is no longer just to build models that know everything, but to build models that can process information with surgical precision and minimal wasted energy. By refining the architectural efficiency of these systems, we can democratize access to high-performance AI, allowing sophisticated tools to run on local hardware and smaller cloud instances rather than requiring massive, dedicated server clusters.

Enter Leanstral 1.5, Mistral’s latest breakthrough in the pursuit of sustainable, high-performance computing. Leanstral 1.5 stands as a critical response to the current climate of “model bloat,” proving that extreme efficiency does not necessitate a compromise in intelligence or reasoning depth. It represents a fundamental recalibration of how we approach model architecture, demonstrating that complex problem-solving and nuanced linguistic understanding can be achieved through clever, condensed design. By bridging the gap between resource-heavy giants and lightweight, underpowered tools, Leanstral 1.5 provides a robust solution for developers and enterprises who refuse to choose between performance and sustainability.
Leanstral 1.5 serves as a beacon for the future of the industry, signaling that the most impactful AI of tomorrow will be defined by its elegance and precision rather than its raw, unchecked scale.
Ultimately, the arrival of this model signifies that the industry is maturing. The focus has shifted from the brute-force expansion that defined the early era of generative AI toward a more sophisticated, engineering-first approach. By lowering the barriers to entry and making top-tier reasoning accessible through a more efficient framework, Leanstral 1.5 is setting a new standard for what it means to build intelligent, scalable, and environmentally conscious technology. As we move forward, this commitment to efficiency will be the defining metric for success in an increasingly crowded and resource-conscious digital landscape.

Leanstral 1.5 marks a definitive departure from the industry’s long-standing obsession with sheer parameter count, signaling a strategic pivot toward architectural intelligence. While the early days of generative AI were defined by a “bigger is better” ethos—where performance was inextricably linked to the gargantuan scale of a model’s training data and weight parameters—Leanstral 1.5 challenges this narrative by prioritizing efficiency at the foundational level. By distilling the research prowess that has become synonymous with Mistral into a hyper-optimized format, this iteration proves that advanced reasoning capabilities do not necessarily require massive server clusters to function effectively.
The technical mandate behind the development of Leanstral 1.5 was to bridge the widening gap between high-end research models and the practical limitations of everyday hardware. Rather than simply shrinking existing architectures, the engineers behind Leanstral 1.5 redesigned the internal mechanics to ensure that every computational cycle contributes directly to output quality. This optimization process focuses on reducing the latency overhead that typically plagues larger models, ensuring that users experience near-instantaneous responses without sacrificing the nuance or accuracy expected from top-tier artificial intelligence.

Distinguishing itself from its predecessors, Leanstral 1.5 acts as a bridge for developers who require enterprise-grade performance but operate within constrained environments. Previous architectures often forced a difficult compromise: sacrificing accuracy to achieve usable speeds or accepting sluggish performance to maintain high-level reasoning. Leanstral 1.5 successfully disrupts this trade-off by implementing refined weight quantization and architectural pruning that maintains the integrity of the model’s logical pathways. This balance allows the model to thrive on edge devices, personal workstations, and cloud instances alike, effectively democratizing access to high-performance AI.
Leanstral 1.5 isn’t just about making things faster; it is about reclaiming the power of advanced intelligence for the user, ensuring that sophisticated reasoning is no longer gated by the scarcity of massive computing resources.
Ultimately, this model represents a shift toward “faster and smarter” as the new gold standard for the industry. By focusing on the elegance of the underlying code rather than just the raw quantity of its parameters, the development team has ensured that Leanstral 1.5 remains adaptable to an evolving hardware landscape. Whether it is deployed in a mobile application, a real-time data processing pipeline, or a local development environment, the model stands as a testament to the belief that the future of AI is not just about scale, but about the efficiency of thought.
The journey towards democratizing advanced AI capabilities hinges significantly on efficiency. Large language models, while incredibly powerful, have historically demanded substantial computational resources, limiting their accessibility and increasing operational costs. With Leanstral 1.5, the engineering team embarked on an ambitious mission to fundamentally redesign the model’s core, not just to enhance performance, but to dramatically reduce its computational footprint. This endeavor involved a multi-pronged approach, meticulously refining the underlying transformer architecture and implementing advanced compression techniques to achieve unparalleled gains in speed and resource management.
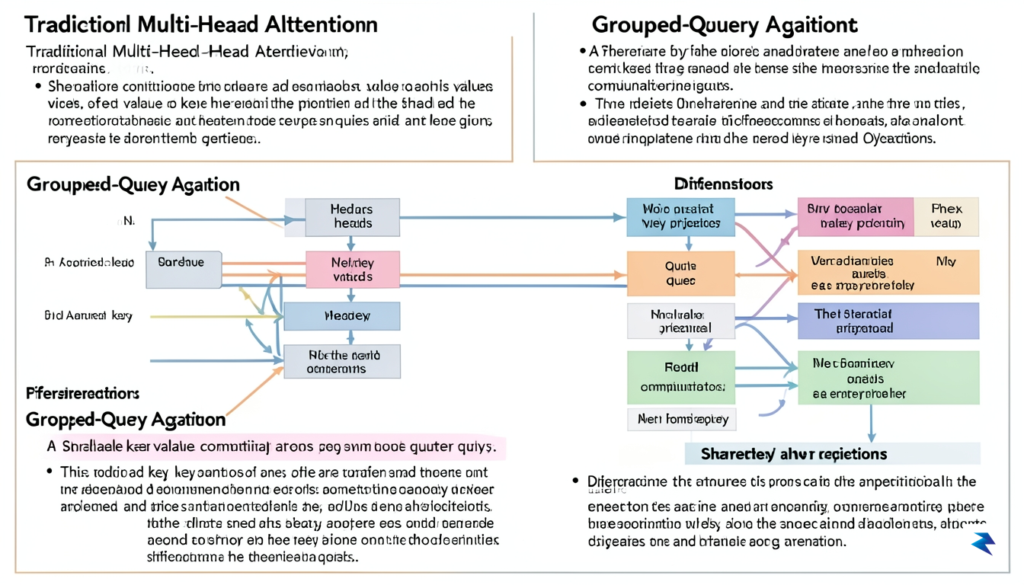
At the heart of Leanstral 1.5’s efficiency lies a series of clever modifications to the foundational transformer architecture. Traditional transformers often employ a multi-head attention mechanism where each “head” processes information independently, leading to a high memory and computational overhead, especially during the key-value projection steps. The Leanstral 1.5 team innovated by implementing techniques such as Grouped-Query Attention (GQA). Instead of each query head having its own key and value projections, GQA allows multiple query heads to share a single set of key and value projections. This seemingly subtle change drastically reduces the number of parameters needed for attention calculations and minimizes the memory bandwidth required to fetch these values, particularly during inference.
Furthermore, careful optimization of the feed-forward networks and activation functions within each layer contributed to a leaner, yet equally expressive, model. These architectural tweaks ensure that the model can process information with fewer redundant computations, translating directly into faster token generation. The result is a model that is not only robust and capable but also inherently more agile, capable of performing complex reasoning tasks without the gargantuan energy expenditure typically associated with state-of-the-art LLMs.
Beyond architectural refinements, Leanstral 1.5 incorporates sophisticated model compression techniques that further trim its computational fat. One key strategy is intelligent pruning, where less critical connections and weights within the neural network are identified and removed without significantly impacting the model’s overall performance. Imagine sculpting a statue: you remove excess material without losing the essence of the form. This process results in a sparser network that requires fewer operations during inference.
Another powerful technique leveraged is knowledge distillation. This involves training a smaller, more efficient “student” model to mimic the behavior and outputs of a larger, more complex “teacher” model. The student learns the valuable knowledge embedded in the teacher, but with a significantly reduced parameter count and computational cost. Finally, quantization plays a crucial role in minimizing the memory footprint. By reducing the numerical precision of the model’s parameters and activations – for instance, from 32-bit floating-point numbers to 8-bit or even 4-bit integers – Leanstral 1.5 can drastically cut down on memory usage and accelerate computations, as lower-precision operations are inherently faster for modern hardware.
“Leanstral 1.5 marks a pivotal shift: powerful AI doesn’t have to be prohibitively expensive. Our innovations mean faster, more accessible intelligence for everyone.”
The impact of these architectural innovations and compression techniques is profoundly evident in Leanstral 1.5’s performance benchmarks. Compared to previous iterations and similarly capable models, Leanstral 1.5 demonstrates a remarkable increase in token generation speed, often delivering responses multiple times faster. This translates into a smoother, more responsive user experience, where waiting times for complex outputs are significantly reduced. Furthermore, the memory overhead has seen a substantial reduction, meaning the model can run effectively on a wider range of hardware, including devices with more modest specifications or within constrained cloud environments.
These efficiency gains are not merely technical curiosities; they have far-reaching implications for the practical deployment and accessibility of advanced AI. By lowering the hardware barrier and reducing the computational resources required, Leanstral 1.5 makes sophisticated generative AI more attainable for individual developers, small businesses, and researchers who may not have access to supercomputer-level infrastructure. It effectively redefines what’s possible on consumer-grade GPUs or even specialized edge devices, paving the way for a future where powerful AI is not a luxury, but an abundant and ubiquitous tool.

At its core, the concept of “Proof Abundance” represents a fundamental pivot in how we perceive the relationship between computational power and artificial intelligence. For years, the industry narrative has been dominated by a “bigger is better” mentality, where intelligence was strictly gated behind the colossal hardware requirements of massive data centers. Mistral’s latest initiative challenges this exclusivity by asserting that high-performance intelligence should be a ubiquitous utility rather than a luxury good. By engineering Leanstral 1.5 to achieve remarkable cognitive depth within a compact footprint, the team is proving that scarcity is not a technical necessity, but a design choice that the industry can—and should—move beyond.
This democratization of AI is not merely a matter of convenience; it is a vital step toward creating a more equitable technological landscape. When powerful models are tethered to enormous energy-hungry clusters, their application is inevitably restricted to the tech giants and well-funded enterprises capable of footing the bill. Leanstral 1.5 shatters this barrier by optimizing intelligence so that it can run on accessible hardware, effectively putting the power of a sophisticated assistant into the hands of individual developers, small businesses, and researchers in emerging markets. This shift ensures that the benefits of the AI revolution are distributed across a wider spectrum of society, rather than being concentrated in the hands of a few gatekeepers.

“True innovation isn’t just about building a larger brain; it is about making that brain agile enough to solve problems wherever they happen to exist, rather than forcing the world to come to the server.”
The societal implications of this shift toward “abundant” intelligence are profound and far-reaching. By drastically reducing the overhead costs of running state-of-the-art models, we enable a surge in localized, private, and specialized AI applications that were previously economically unfeasible. Whether it is a clinic using an on-device model to process diagnostics in a remote area without a stable internet connection, or a student running a sophisticated tutor on a standard laptop, the affordability of Leanstral 1.5 lowers the threshold for entry into the digital economy. Ultimately, this philosophy signals a move toward a world where the quality of an AI’s logic is determined by its design efficiency, allowing humanity to harness the potential of machine learning without the crushing weight of centralized infrastructure requirements.

Leanstral 1.5 marks a significant inflection point for how artificial intelligence can be deployed, fundamentally shifting the landscape for both individual developers and large-scale enterprises. Previously, the deployment of highly sophisticated AI agents was often constrained by the sheer computational power required, relegating them to specialized, high-end cloud infrastructure. This latest iteration, however, shatters those barriers, enabling the seamless operation of powerful models on resource-constrained edge devices and even standard cloud instances that were once deemed insufficient. This breakthrough unlocks a myriad of new possibilities, democratizing access to advanced AI capabilities and paving the way for innovations across various sectors.
For developers, this means the dream of truly intelligent edge computing is now a tangible reality. Imagine deploying advanced natural language processing or intricate computer vision models directly onto smart cameras, industrial IoT sensors, or even consumer-grade drones, performing real-time inference without constant reliance on cloud connectivity. This capability significantly reduces latency, enhances data privacy by processing information locally, and ensures functionality even in disconnected environments. Furthermore, it empowers local AI deployment, allowing advanced assistants, creative tools, and analytical engines to run efficiently on personal laptops and desktops, providing users with robust AI experiences directly on their hardware, independent of internet access or subscription models.
From an enterprise perspective, the implications for cost efficiency and scalability are profound. By dramatically reducing the computational footprint of sophisticated AI models, Leanstral 1.5 directly translates into lower operational expenditures. Businesses can now achieve comparable or even superior performance using less powerful, more energy-efficient hardware, thereby cutting down on cloud infrastructure costs, reducing data egress fees, and minimizing overall energy consumption. This newfound efficiency not only makes AI deployments more sustainable but also enables enterprises to scale their AI initiatives more broadly across their operations, deploying intelligent agents to a wider array of devices and locations without incurring prohibitive costs.
Key takeaway for enterprises: Leanstral 1.5 transforms AI from a resource-heavy investment into an accessible, scalable, and cost-efficient operational asset, fostering innovation without compromising the bottom line.
Integrating this potent new model into existing workflows is designed to be straightforward for developers. Leanstral 1.5 offers flexible APIs and comprehensive libraries, making it relatively easy to fine-tune and embed these efficient agents into diverse applications, from mobile apps to industrial control systems. Developers are encouraged to begin by identifying critical use cases where current AI solutions are either too expensive, too slow, or simply impossible due to hardware limitations. Experimenting with migrating existing cloud-dependent AI tasks to local or edge deployments can quickly demonstrate the tangible benefits in terms of responsiveness and cost savings.
While the efficiency gains are substantial, it’s crucial to approach deployment with a pragmatic understanding of the inherent trade-offs between model performance and size. Leanstral 1.5 provides a spectrum of options, allowing developers to select the optimal balance for their specific application and target hardware. For highly critical, real-time applications on severely constrained devices, a smaller

The arrival of Leanstral 1.5 represents a fundamental shift in the artificial intelligence landscape, moving the industry away from the era of “bigger is better” and toward a more thoughtful, resource-conscious design philosophy. By proving that high-performance intelligence does not require massive, energy-intensive architecture, Mistral has effectively lowered the barrier to entry for developers and organizations alike. This model is not merely an incremental update; it is a vital blueprint for a future where powerful AI can run locally, securely, and sustainably on hardware that already exists in our pockets and data centers. As we look ahead, the emphasis on efficiency will likely become the primary metric by which the next generation of AI models is judged.
This trajectory suggests that the true competitive advantage in AI will belong to those who can extract the most utility from the fewest parameters. As computational costs continue to rise and the environmental impact of large-scale training becomes a greater public concern, the Leanstral approach provides a necessary corrective. By democratizing access to state-of-the-art capabilities, Mistral is ensuring that innovation is no longer the sole province of companies with unlimited capital, but rather a tool available to a broader, more diverse ecosystem of creators. This shift is essential for fostering an inclusive technological landscape where diverse use cases can flourish without the constraint of heavy infrastructure.

The true measure of progress in the AI era is no longer how much compute we can consume, but how much intelligence we can deliver with minimal impact.
Looking forward, the evolution of Mistral’s projects serves as a clear signal that the industry is maturing into a more sustainable phase. We encourage you to stay closely tuned to the ongoing developments within this ecosystem, as the lessons learned here will undoubtedly influence the architecture of all future intelligent systems. Whether you are a developer looking to integrate lean solutions into your own applications or an enthusiast curious about the democratization of tech, the path forward is increasingly defined by precision and elegance. Ultimately, Leanstral 1.5 confirms that in the world of high-stakes artificial intelligence, “small” is indeed the new “big,” paving the way for a smarter, cleaner, and more accessible future for everyone.
You must be logged in to post a comment.