Nuclear Innovation: Assessing the True Impact of Recent Startup Breakthroughs
The New Frontier of Nuclear Innovation For decades, the nuclear energy sector remained trapped in a cycle of stagnation, dominated by massive,…

Many developers view threat modeling as a burdensome bureaucratic hurdle—a mountain of paperwork intended to satisfy compliance officers rather than improve the quality of the software itself. In reality, threat modeling is simply the engineering discipline of thinking through the “what ifs” before you start typing code. It is a structured, intentional process of identifying potential vulnerabilities in your system architecture, mapping out how an attacker might exploit them, and deciding on the necessary mitigations. When treated as a core part of the development lifecycle, it shifts security from an afterthought into a foundational design principle that makes your application naturally more resilient.
The most common misconception regarding this practice is that it is reserved for massive enterprises with dedicated security departments. On the contrary, individual developers and small teams stand to gain the most from it because they often lack the bandwidth to fix massive architectural flaws once a product has already launched. By proactively evaluating your system—asking where data flows, where it is stored, and who has access to it—you move away from the frantic, reactive “patching” cycle. Security by design means that you are architecting a vault, whereas bolt-on security is like trying to attach a padlock to a cardboard box after it has already been compromised.
The cost of fixing a security vulnerability during the design phase is exponentially lower than addressing that same flaw after the code has been deployed to production.
Consider the economic reality of software development: fixing a logic error or an insecure API endpoint during the whiteboarding stage costs nothing but a few hours of collaborative discussion. If that same flaw is discovered after the system is live, it requires emergency sprints, potentially urgent data breach notifications, and a complete refactoring of your codebase. This is why threat modeling is fundamentally a proactive exercise; it allows you to anticipate failures in the logic of your system before they manifest as real-world security incidents. By integrating this mindset into your workflow, you aren’t just writing code—you are building a robust system that can withstand the inevitable attempts to compromise it.
Ultimately, a threat model is not a static document that gathers dust in a digital folder. It is a living, breathing perspective on your application’s surface area. Whether you are sketching out a new microservice or refactoring a legacy module, the act of questioning your own assumptions—”What happens if this input isn’t sanitized?” or “Can this user actually access this database record?”—is what separates a hobbyist from a security-conscious engineer. By systematically identifying these risks early, you empower yourself to make better architectural decisions that prioritize integrity and safety without sacrificing the velocity of your development cycle.

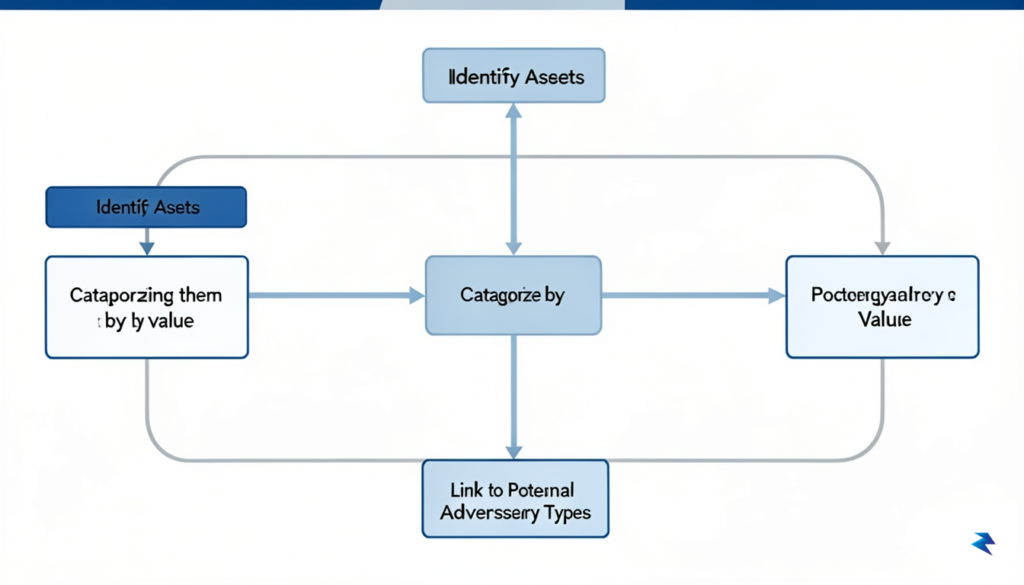
Before you can begin to effectively fortify your digital perimeter, a fundamental question must be answered: what exactly are you trying to protect, and who are you protecting it from? This initial, critical step in developing a robust security posture isn’t about implementing complex technical controls; it’s about clarity and prioritization. Just as a castle builder wouldn’t fortify every stone equally, you cannot defend every piece of data or system with the same intensity. Instead, a successful strategy hinges on a granular understanding of your specific assets and the motivations of the individuals or entities most likely to target them.
The first order of business is conducting a thorough asset inventory. This isn’t merely a list of servers; it’s a detailed catalog of everything valuable within your operational sphere. Think broadly about what constitutes an asset: sensitive customer data, proprietary source code, intellectual property, financial records, employee information, critical infrastructure, brand reputation, and even the availability of your services. For each identified asset, delve into its nature: what specific data does it contain, how sensitive is that data, and what would be the impact if it were compromised, lost, or made unavailable? This level of detail helps establish a foundational understanding of what truly matters.
Once you’ve identified your assets, the next crucial step is to determine where they reside and who has access to them. Is that sensitive customer data stored in a cloud database, on an internal server, or perhaps on an employee’s laptop? Who are the legitimate users who access this data regularly, and through what systems? Furthermore, consider the pathways through which this data might be inadvertently exposed or intentionally exfiltrated. Understanding the data’s lifecycle—from creation to storage, transmission, and eventual deletion—along with its access patterns, provides vital context for later security considerations, helping you pinpoint potential vulnerabilities.
With your assets clearly defined and inventoried, you can begin to categorize them based on their value and criticality. Not all assets are created equal; a public marketing brochure, while an asset, does not carry the same weight as a database containing encrypted financial transactions. Assigning a clear value or sensitivity level to each asset—be it high, medium, or low—allows you to align your protection levels accordingly. This strategic alignment ensures that your most vital information receives the most robust defenses, while less critical assets are still secured, but perhaps with fewer resource-intensive measures, optimizing your security budget and effort.
Moving beyond what you protect, the equally important question is *who* you are protecting it from. Adversaries are not a monolithic entity; they vary widely in their capabilities, resources, and motivations. Understanding these distinctions is paramount to building effective defenses. For instance, the threat posed by an opportunistic “script kiddie” looking for easy targets differs significantly from that of an organized crime syndicate aiming for financial extortion or a sophisticated state-sponsored actor seeking long-term espionage. Each type of adversary employs distinct tactics, techniques, and procedures (TTPs), necessitating a tailored defense strategy.
Categorizing adversaries based on their capability and motivation helps you anticipate potential attacks. Capability refers to their technical skill, financial resources, and access to zero-day exploits or advanced tools. Motivation, on the other hand, defines their end goal, whether it’s financial gain, political disruption, intellectual property theft, or simply causing chaos. A script kiddie might exploit a known vulnerability for bragging rights, whereas an organized crime group might conduct extensive phishing campaigns to gain access to financial systems. By profiling these potential attackers, you can better understand the types of attacks you’re most likely to face and prioritize your defenses against the most relevant threats.
This systematic approach to understanding your potential attackers is often referred to as ‘Threat Actor Profiling.’ It involves creating detailed profiles of the most probable adversaries based on your industry, the value of your assets, and your public profile. For example, if you operate in the defense sector, state-sponsored actors might be a primary concern, whereas an e-commerce platform might prioritize defenses against financially motivated cybercriminals. This profiling helps you to allocate resources more effectively, focusing on security controls that directly counter the TTPs of your most likely and dangerous adversaries. Without this clear understanding, security efforts can become broad, unfocused, and ultimately, less effective.

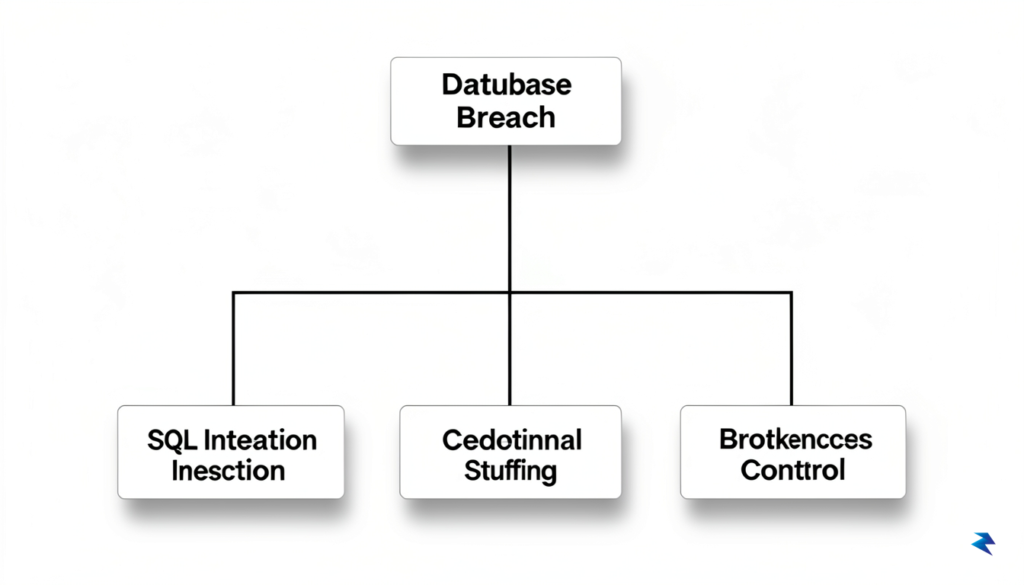
Once you have clearly identified your potential adversaries, the challenge shifts from the theoretical to the mechanical: how do you visualize the paths they might take to compromise your system? This is where attack trees become indispensable. An attack tree is a hierarchical, logical diagram that places your ultimate security goal—such as “unauthorized access to user database”—at the root. From there, you work backward, branching out into the various sub-goals and specific actions an attacker must perform to achieve that final objective. By decomposing a complex threat into granular, testable steps, you transform abstract anxieties into a concrete roadmap of specific vulnerabilities that your team can address through code review, architectural changes, or defensive infrastructure.
To populate your attack tree effectively, you need a structured way to brainstorm potential exploits. The STRIDE model serves as an excellent diagnostic framework for this purpose. By categorizing threats into six distinct types—Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege—you ensure that your threat model covers the full breadth of system weaknesses rather than just the ones that seem most obvious. For instance, when analyzing a login portal, you might use STRIDE to ask: Can an attacker spoof a legitimate user’s identity? Can they tamper with the authentication token? Could a vulnerability lead to information disclosure if the database connection is insecure? Applying these labels systematically prevents the “blind spot” phenomenon that often plagues less structured security audits.
After you have mapped out these potential pathways, the next logical step is to perform a risk assessment by evaluating each node based on two primary metrics: likelihood and impact. Likelihood measures the probability that a specific exploit will be attempted and succeed, taking into account factors like the complexity of the attack and the visibility of the vulnerability. Conversely, impact quantifies the severity of the damage if the breach occurs, considering data loss, service downtime, or legal and reputational consequences. By plotting these nodes on a matrix, you can prioritize your remediation efforts, focusing your limited development resources on the “high-likelihood, high-impact” paths that pose the most immediate danger to your users.
Effective threat modeling isn’t about eliminating every conceivable risk; it is about making informed, strategic decisions to harden the paths that matter most.
Consider a standard web application: an attack tree for the goal of “Exfiltrating User Data” might branch into “Exploiting SQL Injection” or “Bypassing Authentication.” Under the SQL injection branch, you might identify specific inputs that are not sanitized, while under the authentication branch, you might find that session tokens are not properly invalidated. By mapping these out, you aren’t just guessing where the holes are; you are creating a living document that guides your security testing. As your application evolves and new features are added, you can revisit this tree, update the branches, and maintain a rigorous, proactive defense that adapts to the shifting landscape of modern cybersecurity threats.

A beautifully crafted threat model, detailing every potential vulnerability and attack vector, is undoubtedly a valuable artifact. However, its true worth remains untapped if it merely resides as a static document within a project folder. The critical juncture for any security initiative is the transition from theoretical analysis to tangible action. Practical implementation demands that these hard-won insights are not just acknowledged but are actively woven into the very fabric of your team’s daily development workflows, transforming abstract risks into concrete, manageable tasks.
This integration begins by converting the outputs of your threat modeling exercises into actionable development artifacts. Instead of a high-level report, think about creating specific, granular tickets in your project management system – be they Jira tickets, Trello cards, or entries in your backlog. Each identified threat, vulnerability, or required countermeasure should translate into a clear, estimable task. For example, a finding of “lack of input validation” should become several distinct tickets: “Implement robust server-side input validation for all user-provided data in Feature X,” or “Review and harden client-side validation for the user registration form.” These tickets should be prioritized, assigned, and tracked just like any other feature or bug, ensuring security is treated as an intrinsic quality requirement rather than an afterthought.
Furthermore, an application’s threat landscape is rarely static; it evolves alongside new features, architectural changes, and emerging attack techniques. This necessitates a shift from treating threat modeling as a one-time project phase to embracing it as a continuous practice, a cornerstone of a robust DevSecOps culture. Every new feature, significant refactor, or third-party library integration should trigger a mini-threat model review. By embedding security considerations early and often, teams can identify and mitigate risks proactively, preventing costly remediation efforts later in the development cycle. This continuous engagement ensures the security posture remains current and resilient against an ever-changing threat environment.
Achieving this balance, however, often involves navigating a delicate interplay between security, performance, and user experience. Implementing stringent security controls might, in some cases, introduce friction for users or add overhead to system resources. For instance, multi-factor authentication enhances security significantly but adds steps to the login process. The goal is not to achieve perfect, impregnable security at all costs, but rather to implement controls that are proportionate to the identified risks and acceptable within the project’s constraints. This requires thoughtful discussions, often involving product owners, developers, and security experts, to make informed decisions that align with the organization’s risk tolerance and strategic objectives.
To institutionalize this continuous approach, consider scheduling regular ‘threat model review’ sessions. These aren’t just for new features; they’re dedicated times to revisit existing components, assess the efficacy of implemented controls, and scan for new threats that may have emerged since the last review. Whether it’s a monthly security sprint, a dedicated agenda item in sprint reviews, or a pre-release security gate, these recurring checkpoints prevent threat models from becoming stale. They foster a culture where security is a shared responsibility, constantly evaluated and improved upon, ensuring that the application remains secure throughout its lifecycle.

You must be logged in to post a comment.