Ethereum Foundation Restructures: What the 20% Staff Cut Means for the Future
The Shift at the Ethereum Foundation The Ethereum Foundation (EF), long regarded as the bedrock of the world’s most prominent smart-contract…


Anthropic has officially introduced Claude Tag, a specialized utility engineered to transform how developers integrate large language models into sophisticated software architectures. For years, the primary challenge of working with LLMs has been the inherent “black box” nature of unstructured text generation; while models can produce brilliant content, they often struggle to adhere to the rigid, predictable data formats required by enterprise backends. Claude Tag serves as a bridge, allowing developers to apply metadata, categorical labels, and structural anchors directly to the model’s output stream. This evolution marks a significant departure from previous workflows, where developers were forced to rely on brittle prompt engineering or complex post-processing regex scripts to parse AI-generated information.
The core value proposition of this tool lies in its ability to turn chaotic, free-form text into a structured data pipeline. By utilizing Claude Tag, developers can enforce consistency across high-scale AI deployments, ensuring that every output is automatically indexed and categorized according to the specific business logic of their application. Instead of treating an LLM response as a monolithic block of text, the system now views it as a collection of modular, tagged components. This granularity not only speeds up the development lifecycle but also drastically reduces the error rates associated with downstream data ingestion, as the pipeline now knows exactly how to handle and route specific segments of generated content based on their assigned tags.

Claude Tag represents a shift from “conversational AI” to “computational AI,” where the output of a model is treated as a first-class citizen within a structured software ecosystem rather than just a human-readable response.
Furthermore, this tool addresses the growing demand for accountability and auditability in AI workflows. In environments where transparency is paramount—such as financial analysis, medical documentation, or automated legal reviews—being able to categorize and track the origin of specific model outputs is essential. Because Claude Tag embeds metadata directly into the interaction, teams can now trace which specific prompts or configuration parameters led to particular data structures. This level of oversight ensures that as organizations scale their AI usage, they do not lose control over the quality or the predictability of the information being processed. By moving away from unstructured, opaque outputs, Anthropic is effectively professionalizing the role of the LLM, transforming it from a creative assistant into a reliable, predictable engine for enterprise-grade automation.

In the evolving landscape of artificial intelligence, the efficacy of an automation pipeline is fundamentally limited by the quality and structure of the data it receives. Historically, developers have relied on fragile, regex-based parsing to extract meaning from AI-generated text, a process prone to failure whenever the model’s tone or formatting shifts slightly. By acting as a critical middleware layer, Claude Tag injects semantic structure directly into AI outputs, transforming raw natural language into machine-readable data. This shift from unpredictable string parsing to a robust, tag-based identification system ensures that downstream processes can consistently parse, validate, and utilize AI responses without the constant risk of breaking the integration.
The transition toward this structured approach significantly reduces technical debt in AI-driven projects. When systems rely on loose, unstructured text, developers are often forced to write complex, high-maintenance code to handle every possible variation in output. Claude Tag minimizes this overhead by providing a standardized contract between the LLM and the application logic. This reliability allows engineering teams to move away from “hacky” error handling and toward cleaner, more maintainable codebases that focus on business logic rather than constant prompt engineering or response sanitization.
The practical impact of this increased reliability becomes clear when looking at complex automation scenarios. Consider, for example, an automated content management system that processes incoming customer inquiries. By utilizing semantic tags, the system can instantly categorize tickets based on specific metadata generated by the model—such as priority levels or topic identifiers—and route them to the appropriate department via conditional logic. Because the tags act as reliable anchors, the automation engine can trigger specific workflows, such as launching a database query or initiating a customer notification, with near-perfect accuracy.
The true power of AI-driven automation lies not in the generation of text, but in the ability to reliably integrate that generation into a deterministic software architecture.
Ultimately, this approach empowers developers to build more ambitious AI agents that function as dependable components of a larger system. Whether you are automating internal reporting, dynamic content generation, or complex data extraction tasks, the use of semantic markers ensures that the information flowing through your pipeline is both actionable and verifiable. By prioritizing structured output today, teams can avoid the common pitfalls of brittle AI integrations and build a foundation capable of scaling alongside the rapid advancements in large language model capabilities.

At its core, Claude Tag moves beyond the limitations of natural language prompting by allowing developers to define rigorous, structured schemas for AI-generated outputs. While traditional prompting relies on the model’s ability to interpret complex instructions, Claude Tag enforces a formal definition that acts as a blueprint for the response. By explicitly constraining the output space—whether through predefined JSON structures, specific enumeration types, or strictly typed data fields—developers can eliminate the ambiguity that often leads to “hallucinations” or formatting errors. This transition from heuristic-based prompting to schema-enforced generation is a massive leap forward for enterprise-grade applications where the downstream consumption of AI data requires absolute predictability.
The reliability of this generation process cannot be overstated, especially when compared to standard prompt-only instructions. In a typical prompt-based environment, a model might occasionally drift from the requested format, potentially missing a field or misinterpreting a data type, which necessitates expensive post-processing or validation layers. Claude Tag effectively shifts this validation burden to the model’s inference layer itself. By providing the model with a formal schema as part of its operational context, the system ensures that every output adheres to the required shape before it ever reaches the application logic. This tight integration significantly reduces the overhead of custom error-handling code and increases the throughput of reliable, machine-readable responses.
The true power of Claude Tag lies in its ability to treat AI outputs as formal data contracts rather than simple text streams, ensuring that your software ecosystem remains stable even as the underlying models evolve.
For developers, the experience is designed to be as ergonomic as possible, focusing on low-friction integration and high-performance execution. The API handles the complexity of schema mapping behind the scenes, allowing engineers to define their requirements in familiar formats without needing to master complex prompt engineering techniques. Furthermore, Claude Tag is built with latency in mind; by optimizing how the model parses and applies these schemas, the system minimizes the impact on overall response time. Whether you are building a real-time analytics dashboard, an automated content processing pipeline, or a complex customer support agent, the developer-first design ensures that you can maintain rapid iteration cycles without sacrificing the structural integrity of your AI-generated data.
Key technical advantages include:
Adopting new infrastructure often feels like an overwhelming hurdle for engineering teams, particularly when the current LLM stack is already deeply embedded in production. Fortunately, Claude Tag is engineered for seamless interoperability, allowing developers to layer this functionality into existing workflows without the need for a comprehensive architectural rewrite. The integration process typically begins by wrapping your existing API calls with the Claude Tag schema, which acts as a lightweight middleware layer. By simply adjusting your payload structures to include the tag-specific identifiers, you can begin augmenting your prompts with metadata that guides the model’s reasoning process more effectively than standard text-only prompts.
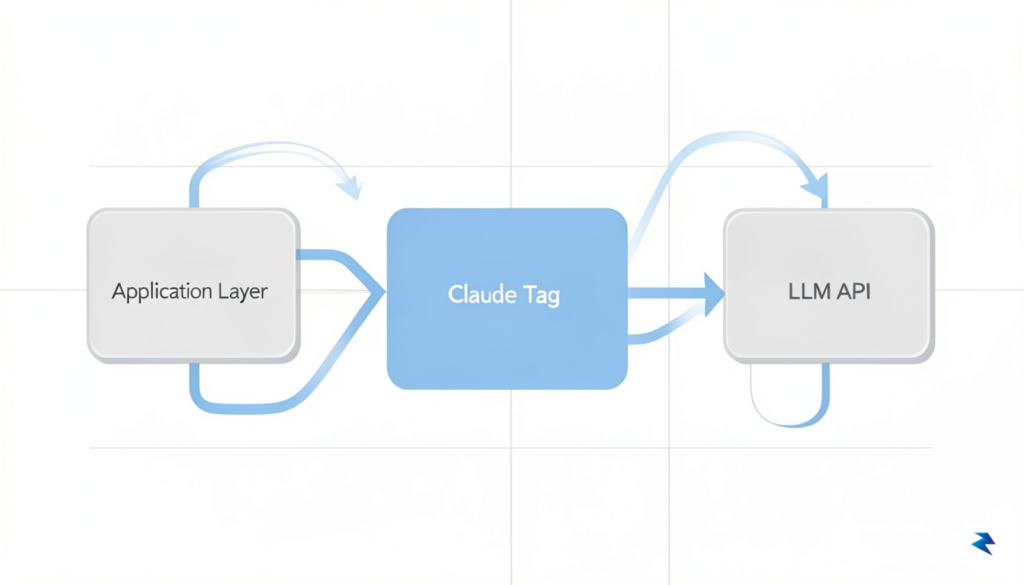
To begin the integration, first map your current prompt templates to the Claude Tag framework, ensuring that the defined tags align with the expected downstream data requirements. Once the mapping is established, you can perform a side-by-side comparison between your standard API calls and the enhanced implementation. Standard calls often suffer from “context pollution,” where the model must parse unstructured instructions alongside raw data, leading to inconsistent outputs. In contrast, the enhanced implementation uses Claude Tag to explicitly demarcate sections of the prompt, providing the model with a clear hierarchy of information. This separation of concerns significantly reduces ambiguity and makes your LLM responses far more predictable in high-stakes production environments.
Key Takeaway: The primary advantage of Claude Tag is not just organizational clarity, but the ability to enforce schema constraints at the prompt level, effectively creating a “contract” between your application code and the LLM.
While the implementation is straightforward, developers should remain vigilant against common pitfalls such as schema mismatch and prompt drift. Schema mismatch occurs when the structured tags in your prompt evolve faster than the parsing logic in your application; to mitigate this, implement a versioning strategy for your tags, ensuring that your code can gracefully handle deprecated or updated schemas. Furthermore, prompt drift—where the model’s behavior subtly changes as you refine your tags—can be mitigated through robust evaluation suites. By maintaining a golden dataset of test cases, you can verify that the integration of Claude Tag improves your model’s accuracy without introducing unexpected side effects. Ultimately, by treating your tags as a versioned component of your codebase, you transform your LLM pipeline from a “black box” into a transparent, manageable asset.

To move beyond basic integration and truly unlock the potential of Claude Tag, development teams must treat their tagging schemas as living, iterative components of their AI architecture. Rather than finalizing a structure during the initial development phase, consider implementing a version-controlled approach to your taxonomy. By continuously evaluating how your tags impact downstream prompt engineering and model output quality, you can refine your schemas to better capture the nuance required for complex enterprise workflows. This iterative cycle ensures that as your business requirements evolve, the metadata remains a precise reflection of your operational goals rather than a static constraint.
Ongoing performance monitoring is equally essential to maintaining long-term ROI. AI models are dynamic, and the effectiveness of your tagging logic can drift if the underlying data patterns change over time. Establish a regular auditing cadence to review the consistency and accuracy of the tags being generated. By tracking metrics such as tag-to-content alignment and the impact of specific metadata on task completion rates, you can identify when it is time to retrain your tagging models or adjust your input parameters. Diligence in this area prevents the degradation of your AI systems, ensuring that they continue to deliver high-quality, reliable outputs throughout their lifecycle.
Success in AI deployment depends less on the initial implementation and more on the robustness of the governance frameworks surrounding your metadata.

In enterprise environments, security and governance must be woven into the fabric of your tagging strategy from day one. Because metadata often contains insights about sensitive data handling or user intent, it is critical to implement strict access controls and audit logs around who can define, modify, or view your tagging schemas. Data provenance—knowing exactly where a tag originated and why—is a cornerstone of responsible AI usage. When you treat metadata with the same security rigor as your primary datasets, you mitigate the risk of unauthorized data exposure and ensure compliance with broader organizational standards. Scalability, therefore, is not merely about handling larger volumes of data; it is about building a sustainable, secure foundation that can grow alongside your organization’s ambitions.
Ultimately, maximizing the value of these tools requires a shift in perspective: view your tagging architecture as a strategic asset rather than a utility. When developers invest time in building modular, well-documented, and secure tagging frameworks, they create a reusable ecosystem that accelerates future projects. This proactive stance reduces technical debt and empowers cross-functional teams to rely on the metadata as a trusted source of truth, effectively bridging the gap between raw unstructured data and actionable AI intelligence.
You must be logged in to post a comment.
